Create a sampler function useful for repeated reproducible sampling
sampler(times, size = 1, replace = FALSE, group = NULL, seed = NULL, key = ".draw", row = ".row", id = ".id", original_id = ".original_id")
Arguments
| times | Number of independent sampling draws to perform. |
|---|---|
| size | Sample size for each random sample. |
| replace | Bool indicating whether sampling should occur with or without replacement. |
| group | An optional expression setting up the grouping to use for bootstrapping. If not provided, any grouping present in the original dataset will be used. |
| seed | Random seed to use. |
| key | Name (as character) of the column that will hold an integer
running from 1 to |
| row | Name (as character) of the column that will hold an integer counting rows in the final bootstrapped dataset. Useful for animations with gganimate. |
| id | Name (as character) of the column that will hold an integer running from 1 to n for each bootstrap, where n is the number of observations in each group. |
| original_id | Name (as character) of the column that indicates the row from which the sampled row originates. |
See also
Examples
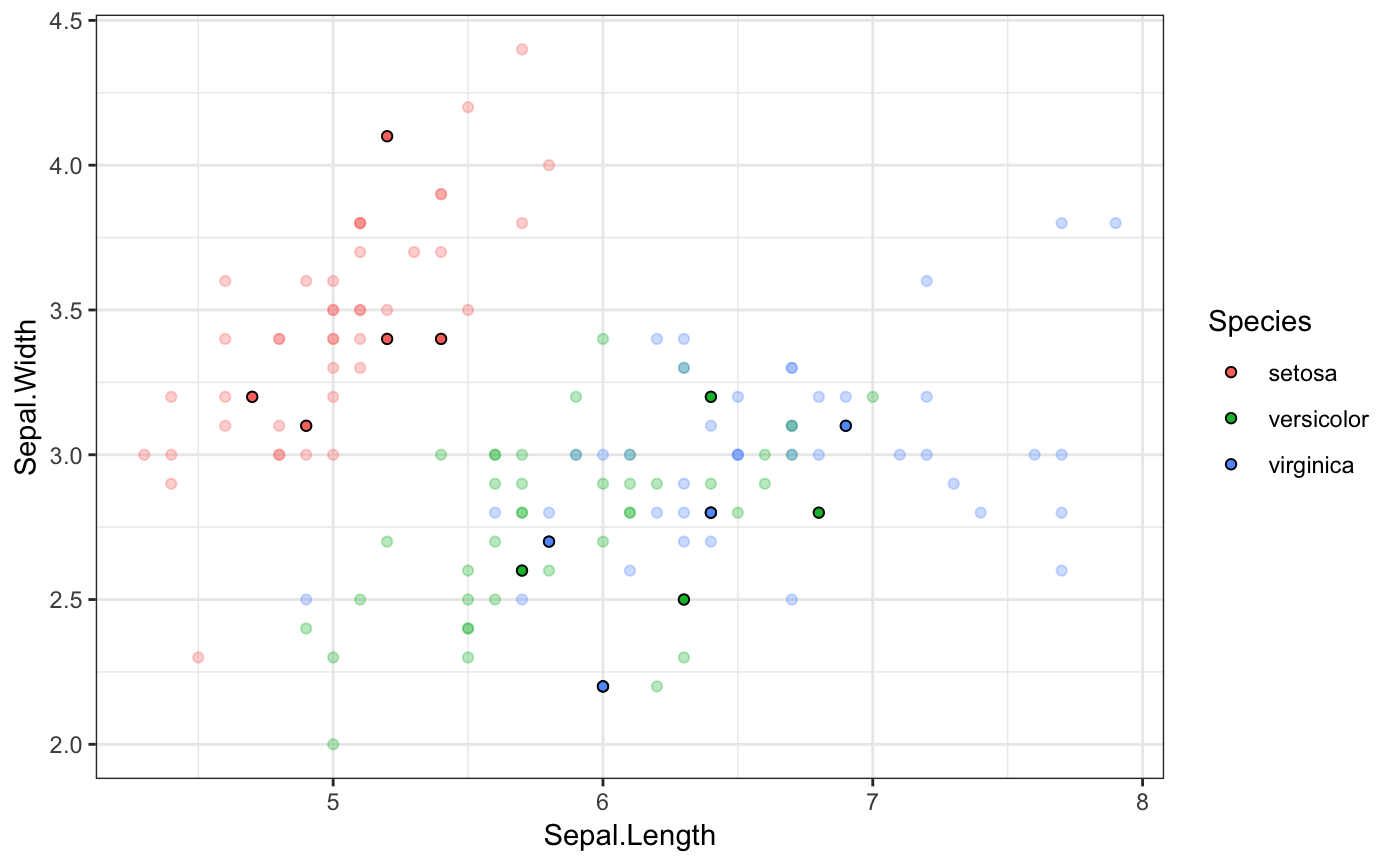
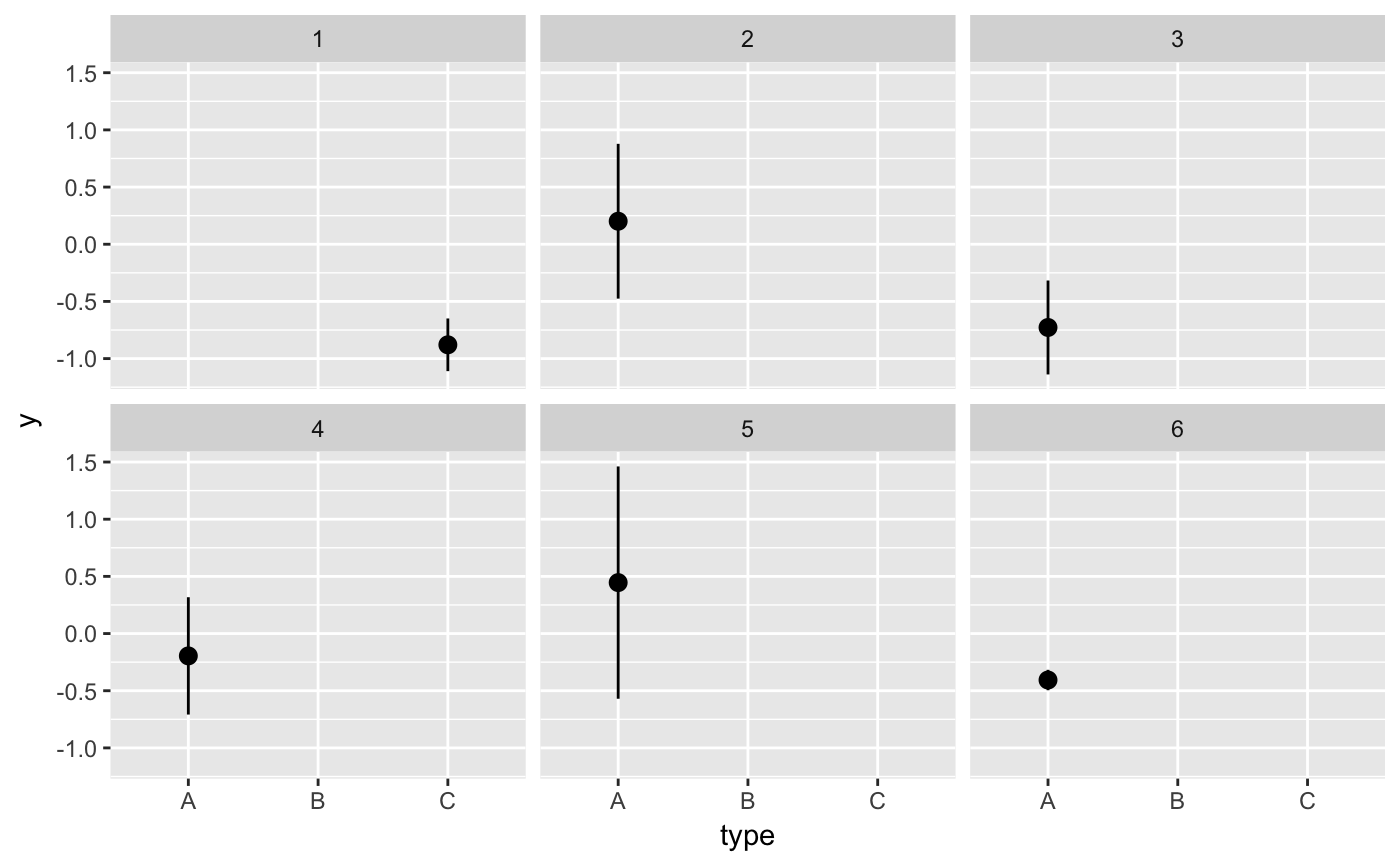
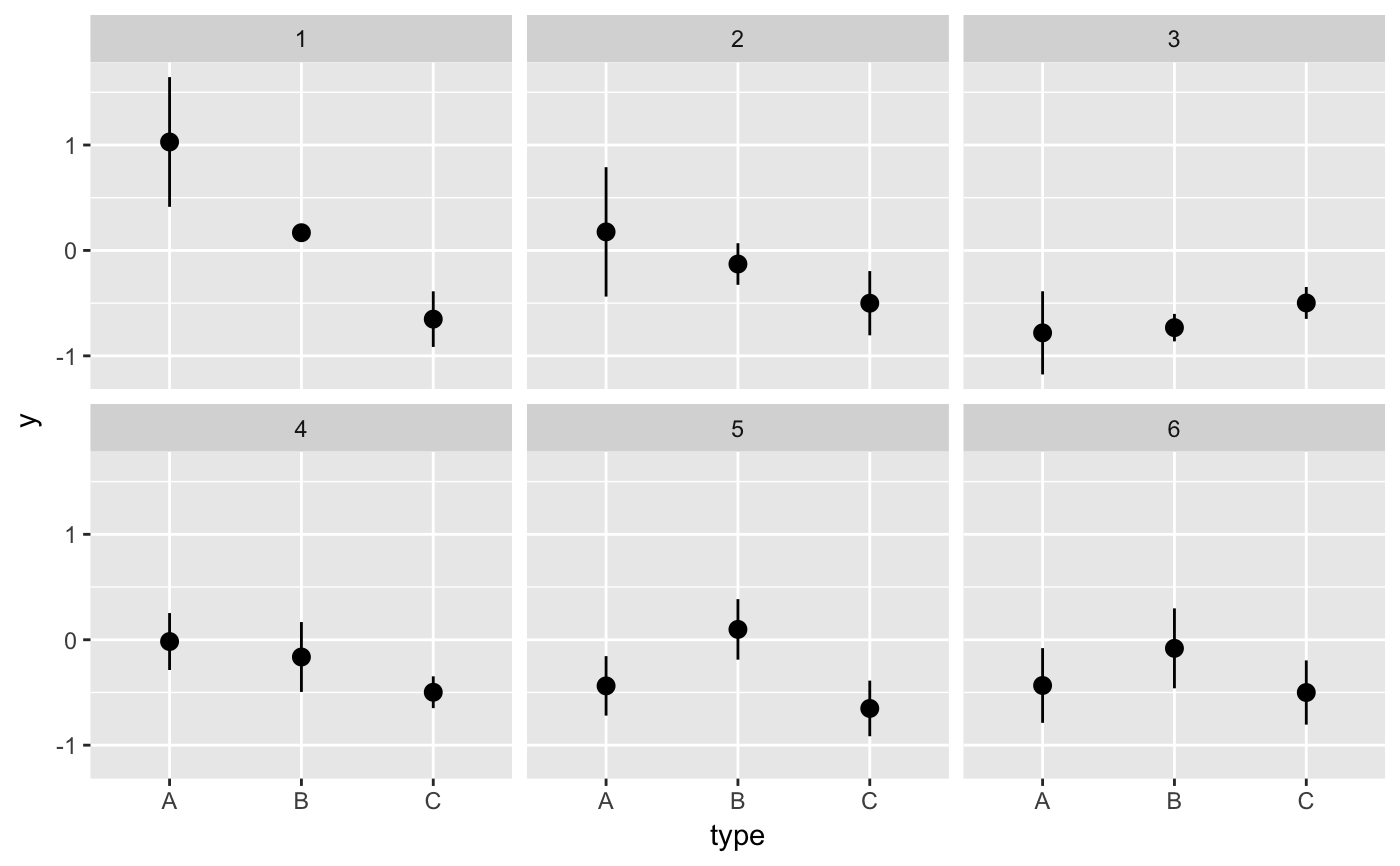
#> # A tibble: 6 x 5 #> # Groups: .draw [3] #> .draw .id .original_id letter .row #> <int> <int> <int> <fct> <int> #> 1 1 1 3 c 1 #> 2 1 2 4 d 2 #> 3 2 1 1 a 3 #> 4 2 2 4 d 4 #> 5 3 1 1 a 5 #> 6 3 2 2 b 6library(ggplot2) library(dplyr) ggplot(iris, aes(Sepal.Length, Sepal.Width)) + geom_point(aes(color = Species), alpha = 0.3) + geom_point( data = sampler(1, 5, group = Species), aes(fill = Species), color = "black", shape = 21 ) + theme_bw()# it is important to set grouping correctly for sampling set.seed(1234) df <- data.frame( type = c(rep("A", 100), rep("B", 10), rep("C", 3)), y = rnorm(113) ) # incorrect: sampling ungrouped dataset leads to missing data # in some categories ggplot(df, aes(type, y)) + geom_pointrange( data = sampler(6, 3, replace = TRUE, seed = 559), stat = "summary" ) + facet_wrap(~.draw)#>#>#>#>#>#>#> Warning: Removed 4 rows containing missing values (geom_pointrange).# correct: sampling within groups ggplot(df, aes(type, y)) + geom_pointrange( data = sampler(6, 3, replace = TRUE, group = type, seed = 559), stat = "summary" ) + facet_wrap(~.draw)#>#>#>#>#>#># also correct: use grouped data frame ggplot(group_by(df, type), aes(type, y)) + geom_pointrange( data = sampler(6, 3, replace = TRUE, seed = 559), stat = "summary" ) + facet_wrap(~.draw)#>#>#>#>#>#># NOT RUN { library(gganimate) p <- ggplot(iris, aes(Sepal.Length, Species, color = Species)) + geom_point(color = "grey50", alpha = 0.3, size = 2) + geom_point(data = sampler(20, 1, group = Species), size = 4) + scale_color_brewer(type = "qual", palette = 2, guide = "none") + theme_bw() p + facet_wrap(~.draw) p + transition_states(.draw, 1, 2) # }